How I Accidentally Became #2 VDP* Researcher for Germany on HackerOne
A candid story about building iteratively with Claude Code and ending up on the HackerOne VDP leaderboard for Germany.
* VDP = Vulnerability Disclosure Program
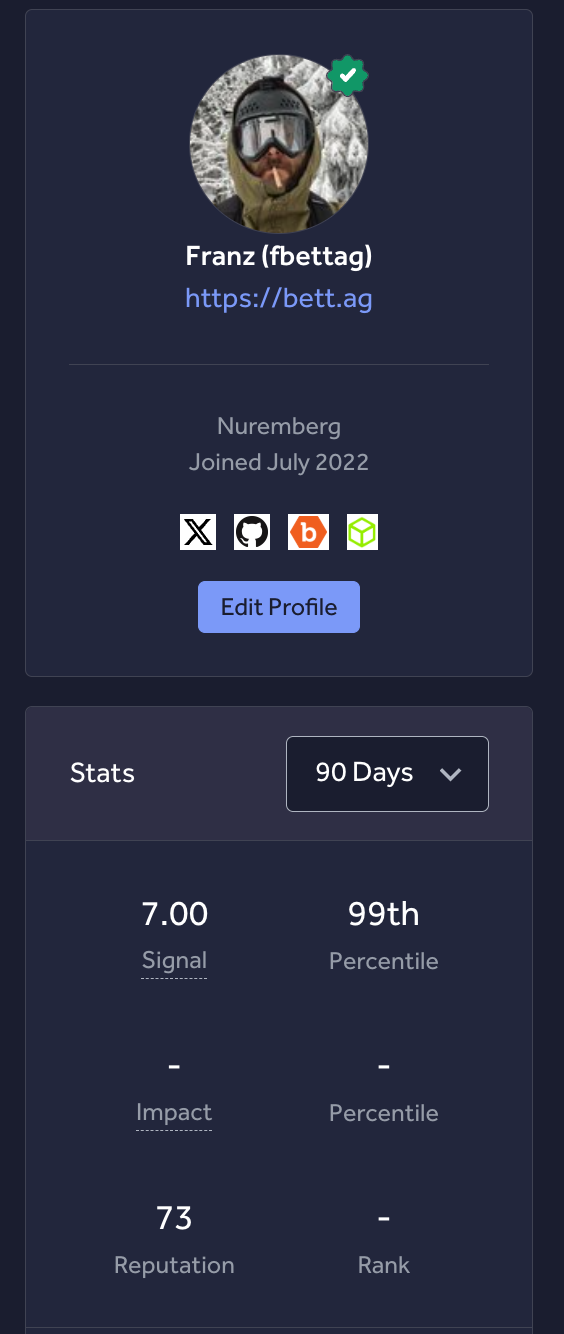
Franz Bettag Polyglot engineer since 2001
25 years of consulting for enterprise to Fortune 500. On-prem, cloud, AI, security, and development — paid projects in 30+ languages before AI came around.
Sole IT Engineer next to the CEO. Re-developed the platform from 2014–2019 serving 30M+ monthly users, then exited to eBay.
Tasked to fix a critical performance bottleneck. Found a $2M+ accounting error while rewriting the system. Cut monthly job runtime from 2+ hours to 5 minutes.
Rebuilt flash-sale push notification infra for the largest fashion retailer in the US. 10M+ concurrent pushes, delivery cut from 2 days to under 10 minutes.
If you recognize my last name, it's probably because my grandfather invented the BobbyCar and was the founder of BIG Spielwaren.

The ranking followed real shipped findings
One canonical backend. Distributed execution.
Central server
State, orchestration, findings, submissions, operator UI.
Agents = identity + method
Full session prompts: exploit-web-attacking, recon-subdomain-discovery, audit-finding-verification, …
Skills = composable building blocks
Reusable techniques: subdomain-takeover-detection, nuclei-scanning, playwright, sqlmap, …
4 pwn hosts + shared CLI
A shared bounty-cli standardizes every host run.
NixOS + flakes
Deterministic infra, reproducible deploys, auditable config.
Validation-first state machine
Every risky phase emits an artifact that must pass a gate.
Don’t start with one giant prompt. Start with a loop.
Security is the example. The architecture is the reusable asset.
 no2vdp.bett.ag
no2vdp.bett.ag